
In recent years, precision agriculture that uses modern information and communication technologies is becoming very popular. Raw and semi-processed agricultural data are usually collected through various sources, such as: Internet of Thing (IoT), sensors, satellites, weather stations, robots, farm equipment, farmers and agribusinesses, etc. Besides, agricultural datasets are very large, complex, unstructured, heterogeneous, non-standardized, and inconsistent. Hence, the agricultural data mining is considered as Big Data application in terms of volume, variety, velocity and veracity. It is a key foundation to establishing a crop intelligence platform, which will enable resource efficient agronomy decision making and recommendations. In this paper, we designed and implemented a continental level agricultural data warehouse by combining Hive, MongoDB and Cassandra. Our data warehouse capabilities: (1) flexible schema; (2) data integration from real agricultural multi datasets; (3) data science and business intelligent support; (4) high performance; (5) high storage; (6) security; (7) governance and monitoring; (8) consistency, availability and partition tolerant; (9) distributed and cloud deployment. We also evaluate the performance of our data warehouse.
You have full access to this open access chapter, Download conference paper PDF
In 2017 and 2018, annual world cereal productions were 2,608 million tons [30] and 2,595 million tons [7], respectively. However, there were also around 124 million people in 51 countries faced food crisis and food insecurity [8]. According to United Nations [29], we need an increase 60% of cereal production to meet 9.8 billion people needs by 2050. To satisfy the massively increase demand for food, crop yields must be significantly increased by using new farming approaches, such as precision agriculture. As reported in [6], precision agriculture is vitally important for the future and can make a significant contribution to food security and safety.
The precision agriculture’s current mission is to use the decision-support system based on Big Data approaches to provide precise information for more control of farming efficiency and waste, such as awareness, understanding, advice, early warning, forecasting and financial services. An efficient agricultural data warehouse (DW) is required to extract useful knowledge and support decision-making. However, currently there are very few reports in the literature that focus on the design of efficient DWs with the view to enable Agricultural Big Data analysis and mining. The design of large scale agricultural DWs is very challenging. Moreover, the precision agriculture system can be used by different kinds of users at the same time, for instance by both farmers and agronomists. Every type of user needs to analyse different information sets thus requiring specific analytics. The agricultural data has all the features of Big Data:
In this research, firstly, we analyze popular DWs to handle agricultural Big Data. Secondly, an agricultural DW is designed and implemented by combining Hive, MongoDB, Cassandra, and constellation schema on real agricultural datasets. Our DW has enough main features of a DW for agricultural Big Data. These are: (1) high storage, high performance and cloud computing adapt for the volume and velocity features; (2) flexible schema and integrated storage structure to adapt the variety feature; (3) data ingestion, monitoring and security adapt for the veracity feature. Thirdly, the effective business intelligent support is illustrated by executing complex HQL/SQL queries to answer difficult data analysis requests. Besides, an experimental evaluation is conducted to present good performance of our DW storage. The rest of this paper is organised as follows: in the next Section, we reviewed the related work. In Sects. 3, 4, and 5, we presented solutions for the above goals, respectively. Finally, Sect. 6 gives some concluding remarks.
Data mining can be used to design an analysis process for exploiting big agricultural datasets. Recently, many papers have been published that exploit machine learning algorithms on sensor data and build models to improve agricultural economics, such as [23,24,25]. In these, the paper [23] predicted crop yield by using self-organizing-maps supervised learning models; namely supervised Kohonen networks, counter-propagation artificial networks and XY-fusion. The paper [24] predicted drought conditions by using three rule-based machine learning; namely random forest, boosted regression trees, and Cubist. Finally, the paper [25] predicted pest population dynamics by using time series clustering and structural change detection which detected groups of different pest species. However, the proposed solutions are not satisfied the problems of agricultural Big Data, such as data integration, data schema, storage capacity, security and performance.
From a Big Data point of view, the papers [14] and [26] have proposed “smart agricultural frameworks”. In [14], the platform used Hive to store and analyse sensor data about land, water and biodiversity which can help increase food production with lower environmental impact. In [26], the authors moved toward a notion of climate analytics-as-a-service by building a high-performance analytics and scalable data management platform which is based on modern infrastructures, such as Amazon web services, Hadoop and Cloudera. However, the two papers did not discuss how to build and implement a DW for a precision agriculture.
Our approach is inspired by papers [20, 27, 28] and [19] which presented ways of building a DW for agricultural data. In [28], the authors extended entity-relationship model for modelling operational and analytical data which is called the multi-dimensional entity-relationship model. They introduced new representation elements and showed the extension of an analytical schema. In [27], a relational database and an RDF triple store, were proposed to model the overall datasets. In that, the data are loaded into the DW in RDF format, and cached in the RDF triple store before being transformed into relational format. The actual data used for analysis was contained in the relational database. However, as the schemas in [28] and [27] were based on entity-relationship models, they cannot deal with high-performance, which is the key feature of a data warehouse.
In [20], a star schema model was used. All data marts created by the star schemas are connected via some common dimension tables. However, a star schema is not enough to present complex agricultural information and it is difficult to create new data marts for data analytics. The number of dimensions of DW proposed by [20] is very small; only 3-dimensions – namely, Species, Location, and Time. Moreover, the DW concerns livestock farming. Overcoming disadvantages of the star schema, the paper [19] proposed a constellation schema for an agricultural DW architecture in order to facilitate quality criteria of a DW. However, it did not describe how to implement the proposed DW. Finally, all papers [19, 20, 27, 28] did not used Hive, MongoDB or Cassandra in their proposed DWs.
In general, a DW is a federated repository for all the data that an enterprise can collect through multiple heterogeneous data sources belonging to various enterprise’s business systems or external inputs [9, 13]. A quality DW should adapt many important criteria [1, 15], such as: (1) Making information easily accessible; (2) Presenting and providing right information at the right time; (3) Integrating data and adapting to change; (4) Achieving tangible and intangible benefits; (5) Being a secure bastion that protects the information assets; and (6) Being accepted by DW users. So, to build an efficient agricultural DW, we need to take into account these criteria.
Currently, there are many popular databases that support efficient DWs, such as such as Redshift, Mesa, Cassandra, MongoDB and Hive. Hence, we are analyzing the most popular and see which is the best suited for our data problem. In these databases, Redshift is a fully managed, petabyte-scale DW service in the cloud which is part of the larger cloud-computing platform Amazon Web Services [2]. Mesa is highly scalable, petabyte data warehousing system which is designed to satisfy a complex and challenging set of users and systems requirements related to Google’s Internet advertising business [10]. However, Redshift and Mesa are not open source. While, Cassandra, MongoDB and Hive are open source databases, we want to use them to implement agriculture DW. Henceforth, the Cassandra and MongoDB terms are used to refer to DWs of Cassandra and MongoDB databases.
There are many papers studying Cassandra, MongoDB and Hive in the view of general DWs. In the following two subsections, we present advantages, disadvantages, similarities and differences between Cassandra, MongoDB and Hive in the context of agricultural DW. Specially, we analyze to find how to combine these DWs together to build a DW for agricultural Big Data, not necessarily best DW.
Cassandra, MongoDB and Hive are used widely for enterprise DWs. Cassandra Footnote 1 is a distributed, wide-column oriented DW from Apache that is highly scalable and designed to handle very large amounts of structured data. It provides high availability with no single point of failure, tuneable and consistent. Cassandra offers robust support for transactions and flexible data storage based on ideas of DynamoDB and BigTable [11, 18]. While, MongoDB Footnote 2 is a powerful, cross-platform, document oriented DW that provides, high performance, high availability, and scalability [4, 12]. It works on concept of collection and document, JSON-like documents, with dynamic schemas. So, documents and data structure can be changed over time. Secondly, MongoDB combines the ability to scale out with features, such as ad-hoc query, full-text search and secondary index. This provides powerful ways to access and analyze datasets.
Hive Footnote 3 is an SQL data warehouse infrastructure on top of Hadoop Footnote 4 for writing and running distributed applications to summarize Big Data [5, 16]. Hive can be used as an online analytical processing (OLAP) system and provides tools to enable data extract - transform - load (ETL). Hive’s metadata structure provides a high-level, table-like structure on top of HDFS (Hadoop Distributed File System). That will significantly reduce the time to perform semantic checks during the query execution. Moreover, by using Hive Query Language (HQL), similar to SQL, users can make simple queries and analyse the data easily.
Although, the three DWs have many advantages and have been used widely, they have major limitations. These limitations impact heavily on their use as agricultural DW.
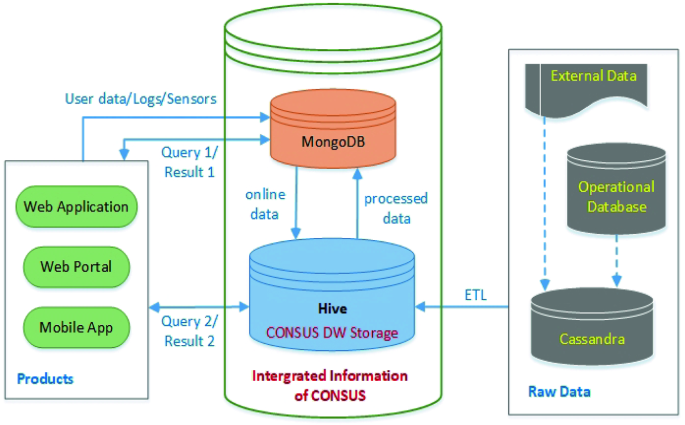
Based on the analyis in Sect. 3, Hive is chosen for building our DW storage and it is combining with MongoDB to implement our Integrated Information module. So, Hive contains database created from the our DW schema in the initialization period. This is for the following reasons:
Our DW architecture for agricultural Big Data is illustrated in Fig. 1 which contains three modules, namely Integrated Information, Products and Raw Data. The Integrated Information module includes two components being MongoDB component and Hive component. Firstly, the MongoDB component will receive real-time data, such as user data, logs, sensor data or queries from Products module, such as web application, web portal or mobile app. Besides, some results which need to be obtained in real-time will be transferred from the MongoDB to Products. Second, the Hive component will store the online data from and send the processed data to the MongoDB module. Some kinds of queries having complex calculations will be sent directly to Hive. After that, Hive will send the results directly to the Products module.
In Raw Data module, almost data in Operational Databases or External Data components is loaded into Cassandra component. It means that we use Cassandra to represent raw data storage. In the idle times of the system, the update raw data in Cassandra will be imported into Hive through the ELT tool. This improves the performance of ETL and helps us deploy our system on cloud or distributed systems better.
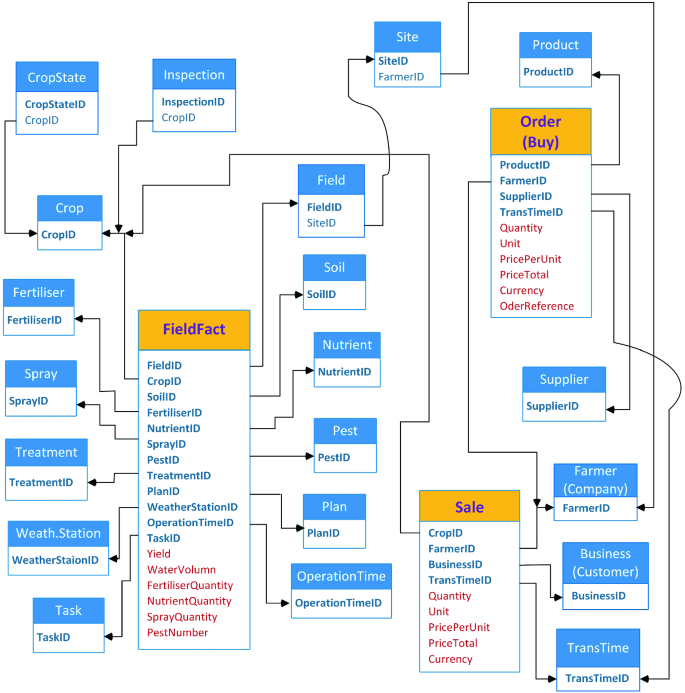
The DW uses schema to logically describe the entire datasets. A schema is a collection of objects, including tables, views, indexes, and synonyms which consist of some fact and dimension tables [21]. The DW schema can be designed through the model of source data and the requirements of users. There are three kind of schemas, namely star, snowflake and constellation. With features of agricultural data, the agricultural DW schema needs to have more than one fact table and be flexible. So, the constellation schema, also known galaxy schema, is selected to design our DW schema.
We developed a constellation schema for our agricultural DW and it is partially described in Fig. 2. It includes 3 fact tables and 19 dimension tables. The FieldFact fact table contains data about agricultural operations on fields. The Order and Sale fact tables contain data about farmers’ trading operations. The FieldFact, Order and Sale facts have 12, 4 and 4 dimensions, and have 6, 6 and 5 measures, respectively. While, dimension tables contain details about each instance of an object involved in a crop yield.
The main attributes of these dimension tables are described in the Table 3. The key dimension tables are connected to their fact table. However, there are some dimension tables connected to more than one fact table, such as Crop and Farmer. Besides, the CropState, Inspection and Site dimension tables are not connected to any fact table. The CropState and Inspection tables are used to support the Crop table. While, the Site table supports the Field table.
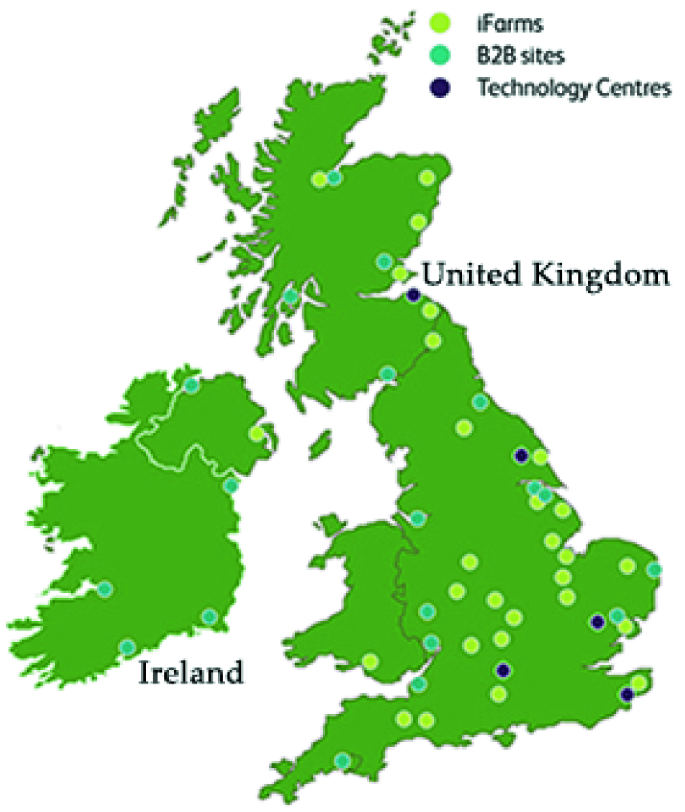
Through the proposed architecture in Sect. 4.2, our DW inherited many advantages from Hive, MongoDB and Cassandra presented in Sect. 3, such as high performance, high storage, large scale analytic and security. In the scope of this paper, we evaluated our DW schema and data analysis capacity on real agricultural datasets through complex queries. In addition, the time performance of our agricultural DW storage was also evaluated and compared to MySQL on many particular built queries belonging to different query groups.
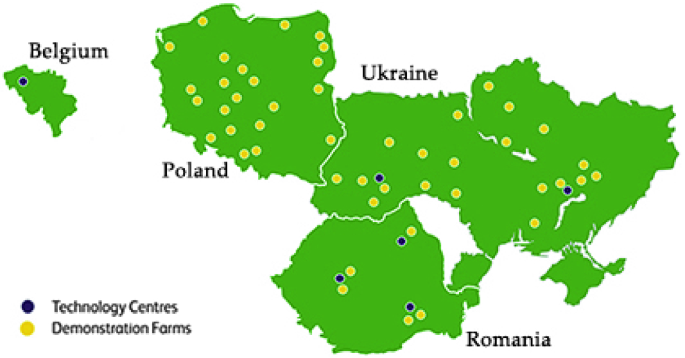
The input data for the DW was primarily obtained from an agronomy company which supplies data from its operational systems, research results and field trials. Specially, we are supplied real agricultural data in iFarms, B2B sites, technology centres and demonstration farms. Their specific positions in several European countries are presented in Figs. 3 and 4 [22]. There is a total of 29 datasets. On average, each dataset contains 18 tables and is about 1.4 GB in size. The source datasets are loaded on our CONSUS DW Storage based on the schema described in Sect. 4.3 through an ETL tool. From the DW storage, we can extract and analyze useful information through tasks using complex HQL queries or data mining algorithms. These tasks could not be executed if the separate 29 datasets have not been integrated into our DW storage.
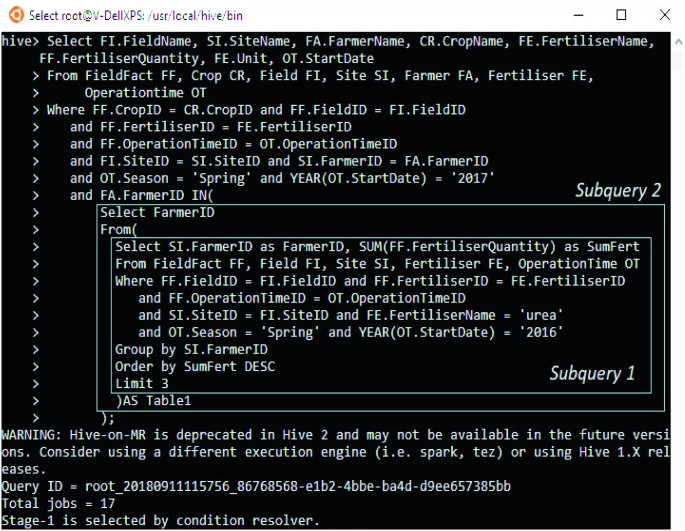
An example for a complex request: “List crops, fertilisers, corresponding fertiliser quantities in spring, 2017 in every field and site of 3 farmers (crop companies) who used the large amount of Urea in spring, 2016”. In our schema, this query can be executed by a HQL/SQL query as shown in Fig. 5. To execute this request, the query needs to exploit data in the FieldFact fact table and the six dimension tables, namely Crop, Field, Site, Farmer, Fertiliser and OperationTime. The query consists of two subqueries which return 3 farmers (crop companies) that used the largest amount of Urea in spring, 2016.
The performance analysis was implemented using MySQL 5.7.22, JDK 1.8.0_171, Hadoop 2.6.5 and Hive 2.3.3 which run on Bash on Ubuntu 16.04.2 on Windows 10. All experiments were run on a laptop with an Intel Core i7 CPU (2.40 GHz) and 16 GB memory. We only evaluate reading performance of our DW storage because a DW is used for reporting and data analysis. The database of our storage is duplicated into MySQL to compare performance. By combining popular HQL/SQL commands, namely Where, Group by, Having, Left (right) Join, Union and Order by, we create 10 groups for testing. Every group has 5 queries and uses one, two or more commands (see Table 4). Besides, every query also uses operations, such as And, Or, \(\ge \) , Like, Max, Sum and Count, to combine with the commands.
All queries were executed three times and we took the average value of the these executions. The different times in runtime between MySQL and our storage of query \(q_i\) is calculated as \(Times_ = RT^_/RT^_\) . Where, \(RT^_\) and \(RT^_\) are respectively average runtimes of query \(q_i\) on MySQL and our storage. Besides, with each group \(G_i\) , the different times in runtime between MySQL and our storage \(Times_ = RT^_/RT^_\) . Where, \(RT_ = Average(RT_)\) is average runtime of group \(G_i\) on MySQL or our storage.
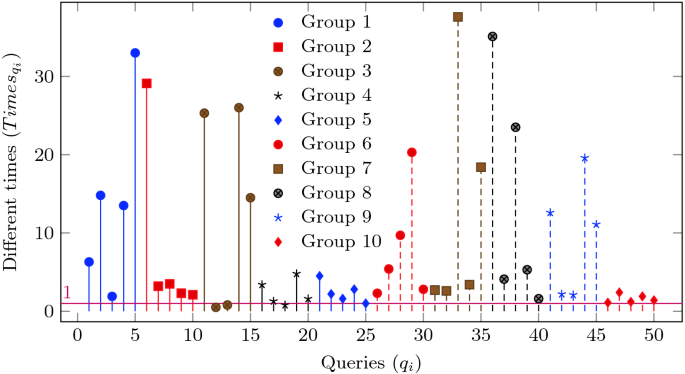
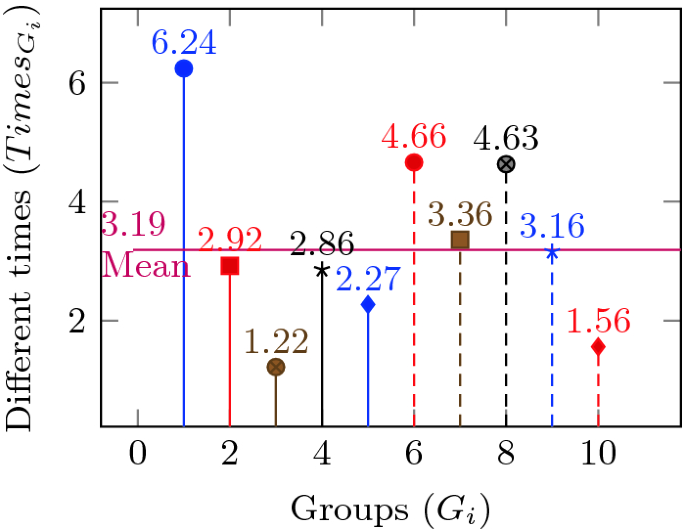
Beside comparing runtime in every query, we aslo compare runtime of every group presented in Fig. 7. Comparing to MySQL, our storage is more than at most (6.24 times) at group \(1^\) which uses only Where command, and at least (1.22 times) at group \(3^\) which uses Where and Joint commands.
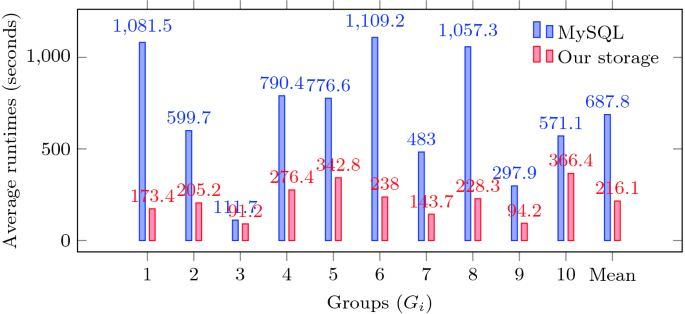
Figure 8 presents the average runtime of the 10 query groups on MySQL and our storage. Mean, the run time of a reading query on MySQL and our storage is 687.8 s and 216.1 s, respectively. It means that our storage is faster 3.19 times. In the future, by deploying our storage solution on cloud or distributed systems, we believe that the performance will be even much better than MySQL.
In this paper, we compared and analyzed some existing popular open source DWs in the context of agricultural Big Data. We designed and implemented the agricultural DW by combining Hive, MongoDB and Cassandra DWs to exploit their advantages and overcome their limitations. Our DW includes necessary modules to deal with large scale and efficient analytics for agricultural Big Data. Additionally, the presented schema herein was optimised for the real agricultural datasets that were made available to us. The schema been designed as a constellation so it is flexible to adapt to other agricultural datasets and quality criteria of agricultural Big Data. Moreover, using the short demo, we outlined a complex HQL query that enabled knowledge extraction from our DW to optimize of agricultural operations. Finally, through particular reading queries using popular HQL/SQL commands, our DW storage outperforms MySQL by far.
In the future work, we shall pursue the deployment of our agricultural DW on a cloud system and implement more functionalities to exploit this DW. The future developments will include: (1) Sophisticated data mining techniques [3] to determine crop data characteristics and combine with expected outputs to extract useful knowledge; (2) Predictive models based on machine learning algorithms; (3) An intelligent interface for data access; (4) Combination with the high-performance knowledge map framework [17].


